Vertebrate Database and Model Review
Accepting external review of vertebrate database and spatial models.Reviewer's will need Microsoft Access and an internet connection in order to access the Reviewer Database (see below). The database is a tool for reviewers to assess species ' models by examining individual model parameters. The interface has been developed to guide reviewers through the process and summarize responses using the Bayesian framework. The database and a user manual are available below. Please read through the Reviewer Manual and review the contents of this webpage to familiarize yourself with the SE-GAP dataset. Hardcopy materials are available, if needed.
If you are interested in hosting a reviewer workshop at your organization, please contact us to arrange.
Reviewer Resources: | Draft Species Maps: | |
| Amphibian Species | ||
| Avian Species | ||
| Mammalian Species | ||
| Reptilian Species |
For More Information:
| Contact: Steve Williams | Contact: Matt Rubino | |||
| Vertebrate Mapping Coordinator | Biologist, GIS and Database Specialist | |||
| 220 David Clark Labs | 214 David Clark Labs | |||
| Biodiversity and Spatial Information Center | Biodiversity and Spatial Information Center | |||
| Department of Biology, NCSU | Department of Biology, NCSU | |||
| Raleigh, NC 27695-7617 | Raleigh, NC 27695-7617 | |||
| 919-513-7413 | 919-513-7280 | |||
| steve_williams@ncsu.edu | matt_rubino@ncsu.edu |
Overview of Review Process
The purpose of model review by external experts is both to inform the process with which models are developed and potentially revised, and to provide users confidence that species models are accurate and useable within the scale and context they are intended. That being said, the review process itself needs to be kept relatively simple and concise while at the same time assessing major model components and overall performance.
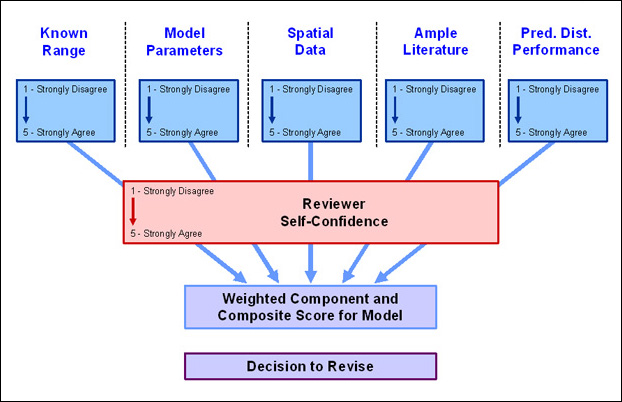
We have chosen to conduct model review in a Bayesian Belief Network Framework so model development and review are more transparent. This allows both modelers and users to understand which aspects of the model are stronger or weaker than others and quantifies the assessment for comparison and usability. Initially, model developers ranked model components a priori (Figure 1). This internal appraisal can then be compare to outside assessment.

Ranking Model Components
Reviewers are asked to respond to six questions ranking their level of agreement on a scale of 1 to 5:
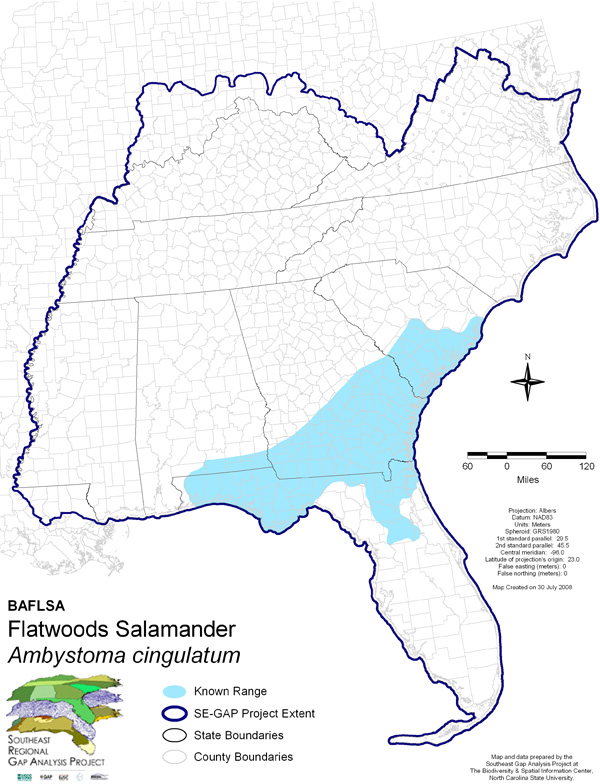
- The delineated geographic range is an accurate representation of the known range extent of the species (Figure 2).
We are defining the known range as the geographical area that is regularly used by a species. It does not include transient or migratory sightings. - The parameters used to model the predicted distribution of the the species accurately represent its habitat requirements in the Southeastern United States (Figure 3).
In otherwords, do you agree that the selection of map units and ancillary data parameters are the best 'formula' for a species habitat? - The spatial data adequately represent the species' habitat requirements (Figure 4).
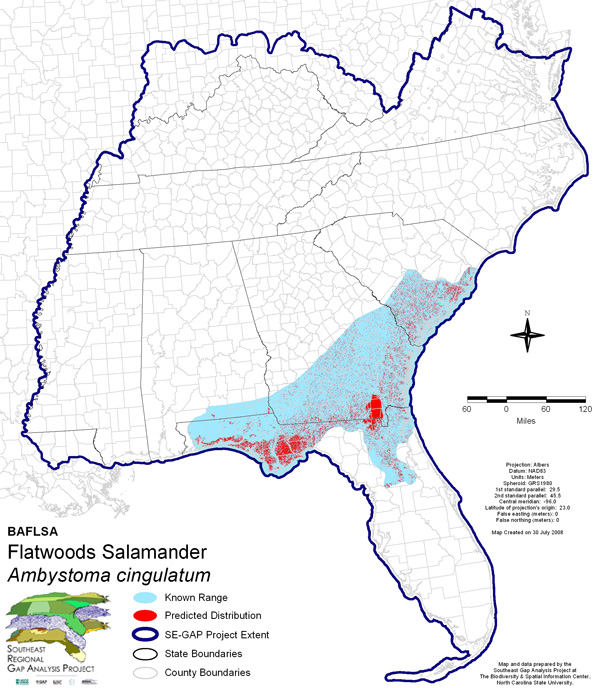
- The mapped predicted distribution adequately represents the distribution of the species' habitat within the identified range extent (Figure 5).
- The published literature adequately documents the breeding habitat requirements for the species in the Southeastern United States.
- I am an expert in the natural history of the species.

Combining and Evaluating Scores
Within the Bayesian framework, reviewer responses to the first five questions are weighted by the reveiwer's self-confidence to produce a weighted composite score for a given model (Figure 6).
Return to Top
Last updated: October 14, 2008